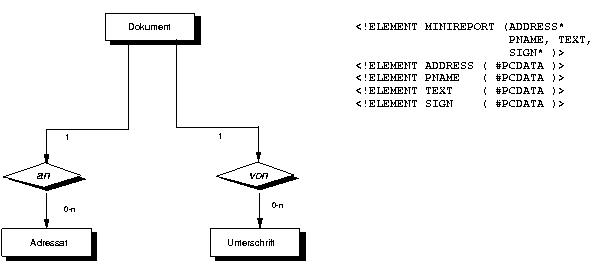
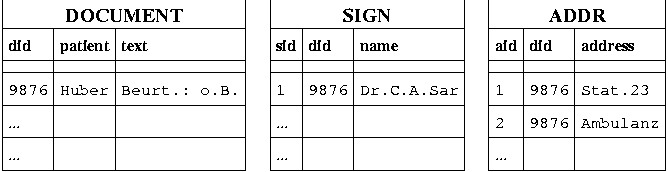
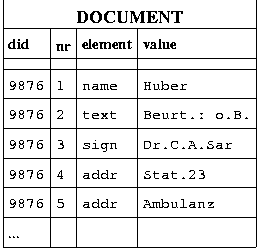
|
ACH
|
Association for Computing in the
Humanities
|
|
ACL
|
Association for Computational
Linguistics
|
|
ACR/NEMA
|
American College of Radiology /
National Electrical Manufacturing
Asociation
|
|
ALLC
|
Association for Literary and Linguistic
Computing
|
|
AML
|
Astronomical Markup Language
|
|
ANSI
|
American National Standards Institute
|
|
ASCII
|
American Standard Code for Information
Interchange
|
|
ASTM
|
American Society for Testing and
Materials
|
|
AWT
|
Abstract Window Toolkit
|
|
ATA
|
Air Transport Association of America
|
|
CERN
|
Conseil Européen pour la Recherche
Nucléaire
|
|
CGI
|
Common Gateway Interface
|
|
CML
|
Chemical Markup Language
|
|
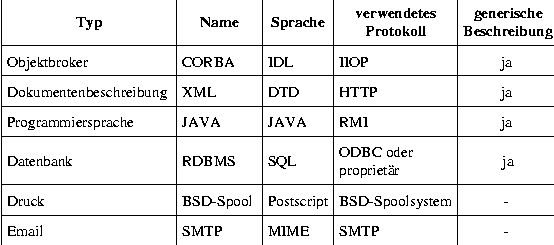
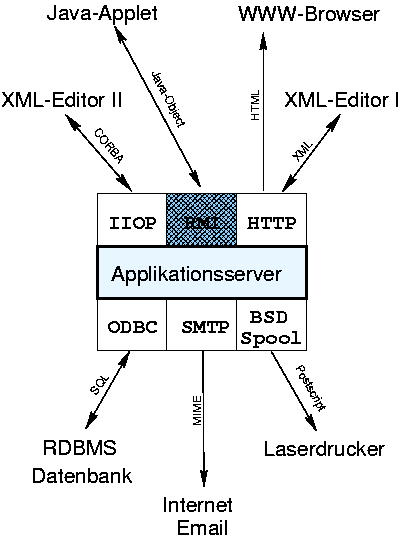
CORBA
|
Common Request Broker Architecture
|
|
CORE
|
Chemistry Online Retrieval Experiment
|
|
CSA
|
Client Server Architektur
|
|
CSS
|
Cascading Style Sheets
|
|
DBMS
|
Datenbank Management System
|
|
DCOM
|
Distributed Component Object Model
|
|
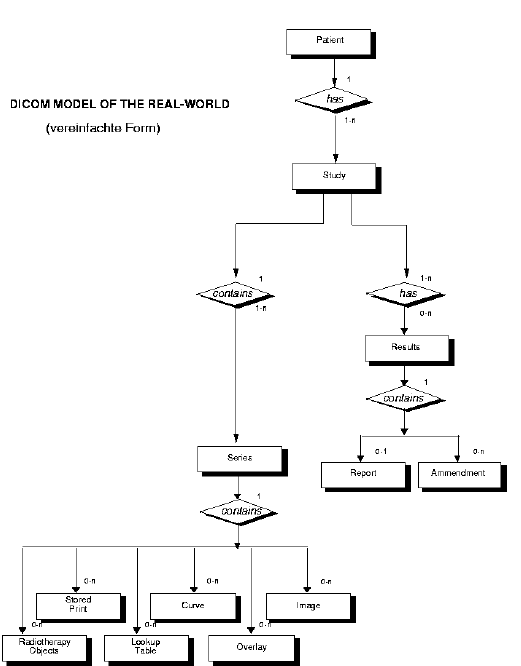
DICOM
|
Digital Imaging and Communications in
Medicine
|
|
DIN
|
Deutsche Industrie-Norm
|
|
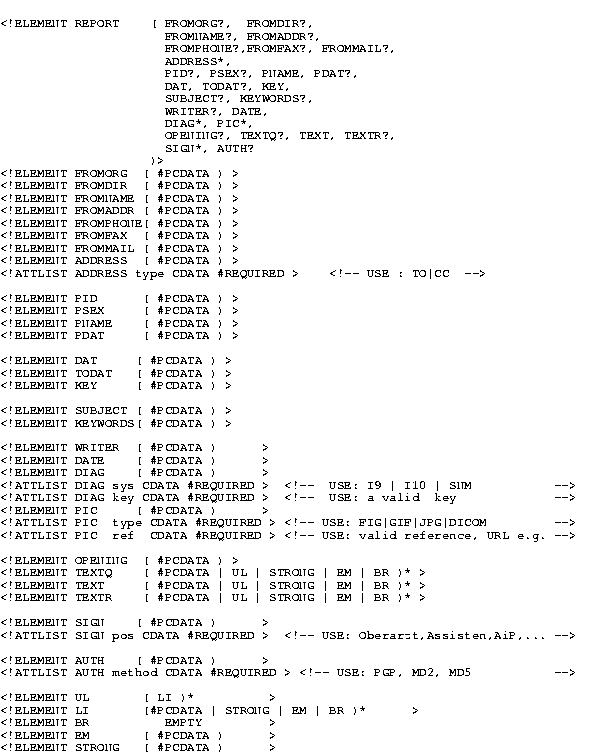
DTD
|
Document Type Definition
|
|
DSSSL
|
Document Style Semantic and
Specification Language
|
|
DTP
|
Desk Top Publishing
|
|
EBCDIC
|
Extended Binary Coded Decimal
Information Code
|
|
EBNF
|
Erweiterte Backus Naur Form
|
|
ECMA
|
European Computer Manufacturer's
Association
|
|
EDI
|
Elektronic Data Interchange
|
|
EDIFACT
|
Electronic Data Interchange For
Administration, Commerce and Transport
|
|
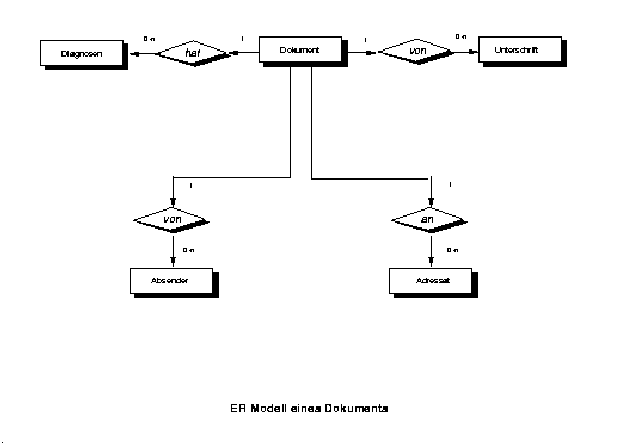
ER
|
Entity Relationship
|
|
GML
|
Generalized Markup Language
|
|
GUI
|
Graphic User Interface
|
|
GNU
|
GNU is not UNIX
|
|
HISPP
|
Health Informatics Standards Planning
Panel
|
|
HL7
|
Health Level Seven
|
|
HTML
|
Hypertext Markup Language
|
|
HTTP
|
HyperText TransportProtokoll
|
|
IDL
|
Interface Definition Language
|
|
ICD
|
International Classification of Disease
|
|
IEEE
|
Institute of Electrical and Electronic
Engineers
|
|
ISO
|
International Standards Organization
|
|
IT
|
Informations Technologie
|
|
KIS
|
Klinik Informations System
|
|
MD5
|
Message Digest 5
|
|
MEDIX
|
Medical Data Interchange Standard
|
|
MSDS
|
Message Standards Developers Subcomittee
|
|
NCPDP
|
National Council of Prescription Drug
Programs
|
|
ODA
|
Office Document Architecture
|
|
ODBC
|
Open DataBase Connectivity
|
|
ODIF
|
Office Document Interchange Format
|
|
OEB
|
Open eBook
|
|
OMG
|
Object Managment Group
|
|
ORB
|
Object Request Broker
|
|
OSI
|
Open Systems Interconnect
|
|
PI
|
Processing Instructions
|
|
RDBMS
|
Relationales DBMS
|
|
RFC
|
Request For Comments
|
|
RIF
|
Railroad Industry Forum
|
|
RIP
|
Raster Image Processor
|
|
RIS
|
Radiologie Informations System
|
|
RMI
|
Remote Method Invokation
|
|
RTF
|
Rich Text Format
|
|
SGML
|
Standard Generalized Markup Language
|
|
SMTP
|
Send Mail Transfer Protokoll
|
|
SNOMED
|
Systematized Nomenclature of Human and
Veterinary Medicine
|
|
SQL
|
Structured Query Language
|
|
SR
|
Structured Reporting
|
|
SSML
|
Speech Synthesis Markup Language
|
|
TCP/IP
|
Transmission Control Protocol /
Internet Protocol
|
|
TEI
|
Text Encoding Initiative
|
|
XML
|
Extensible Markup Language
|
|
XSL
|
Extensible Stylesheet Language
|
|
XSLT
|
XSL Transformations
|
|
UCS
|
Universal Character Set
|
|
UML
|
Unified Medical Language
|
|
UTF
|
UCS Transformation Format
|
|
YACC
|
Yet Another Compiler Compiler
|